How does it work?
The benchmark compares the user manually validated values with the machine’s extracted values and shows the differences between the old and new training models after manual validation.
How is the Benchmark setup?
The Benchmark is provided in an Excel file. The Excel file consists of the following sheets:
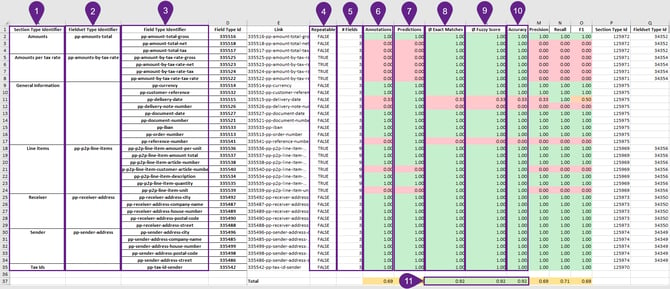
Overview
- Section type identifier
The section type identifier references the section name in the document type. - Fieldset type identifier
Identifier of the field set used in the section. - Field type identifier
Identifier for the field according to the document type. - Repeatable
Information if the field is repeatable. - #Fields
The Fields column shows how many times this field was extracted. - Annotations
The annotations show how many times a user has found the field. - Predictions
The predictions show how many times the machine has found the field. - Exact Matches
The exact matches compare the user annotations with the machine predictions. The value displayed here is the number of annotations that have matched the predictions. - Fuzzy Score
The fuzzy score is similar to the exact matches, but predictions that almost match the annotations are considered here as correct. - Accuracy
The accuracy also shows the same information as the exact matches. - Total
The total shows the extraction quality of all the fields in the document type.
Per Document
The "per document" sheet provides a quality rating based on the information of each field in the document.
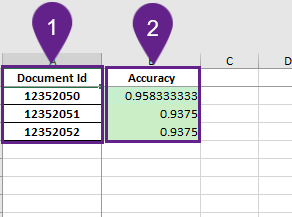
- Document ID
The document ID allows us to identify a document on the platform. - Accuracy
The accuracy tells us how good the extraction was per document.
Fields
The Field sheets provide an in-depth view of each document and what has been extracted by the machine, and what has been extracted by the user.

- Document ID
The document ID allows us to identify a document on the platform. - Repetition
The repetition is the identification of each entry in a document. - Predicted Value
The value that the machine has predicted. - Ground Truth Value
The ground truth value is the value that the user has selected. - Exact Match
The exact match tells us if the predicted and ground truth values match. - Fuzzy Score
The fuzzy score tells us how similar the values are to each other - Location
The last rows show where the information was found in the document, and the ground truth location is compared to the predicted value.
How to analyze a benchmark
The information in the benchmark can be used to analyze the quality of the machine's extractions. The first step of the analysis is reviewing the overview sheet. The value that determines the quality of a field the most is the exact match. Therefore, finding fields with a low exact match average is the first step. Afterwards a deeper analysis in the specific fields sheet is recommended.
Requesting a Benchmark
The benchmark can be requested over the Parashift Support (support@parashift.io). The following information has to be provided:
- Tenant ID
- Document Type
- Time-line or Document IDs