Every uploaded document and batch runs through the same workflow steps. Depending on the use case some steps can be turned off or be very extensive.
Workflow Description
Below is a high-level diagram that explains the different workflow steps:
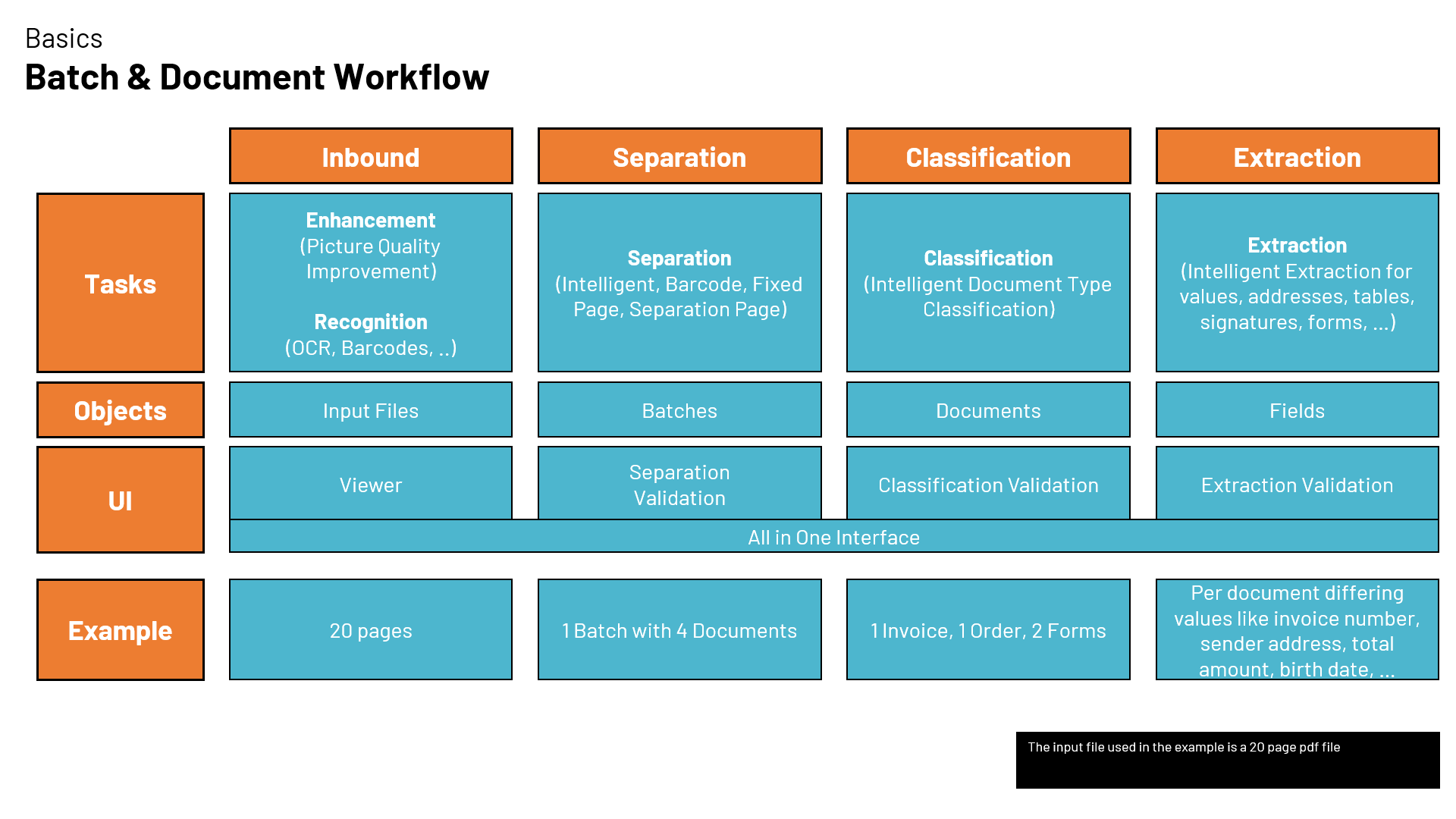
-
Inbound
This is a technical step that prepares incoming files for further processing. Files are converted into an internal working format and enhanced to remove skew, rotation, or background.
One key task here is Optical Character Recognition (OCR), which converts text on images into machine-readable text. -
Separation
If you work only with already separated documents (e.g., single-page PDFs), you can skip this step. Otherwise, a batch (multiple documents uploaded together) is separated into individual documents.- Separation can be purely manual or automated by various methods.
- You can also revisit separation later if a user notices a document is not properly separated.
-
Classification
If you already know which document type you’re processing, this step can be skipped. Otherwise, documents are classified into different document types. Users interact only with exceptions that aren’t classified automatically. -
Extraction
This is the most important step for many users, though it can be skipped if you only need separated and classified documents. Data is extracted from the document based on configured fields. Users can capture fields manually or validate fields with low prediction confidence.- Parashift offers many configuration options and standard document types/fields out of the box.
Data Model
Three attributes describe a document’s current status and workflow step:
| Attribute | Allowed Values | Description |
| status |
pending, in_progress, done, failed |
Overall document status, typically in_progress or done |
| workflow_step |
inbound, inbound_processing, ocr, classification, classification_validation, extraction, extraction_validation, outbound_processing, done, qc |
The current workflow step |
| workflow_status | started in_progress retry failed done |
The current status of the workflow_step |
Examples of Common Workflow & Status Combinations
| status | workflow_step | workflow_status | Description |
| done | done | done | The document is completely processed. All data, including export files, document type, and field data, can be retrieved. |
| in_progress |
classification_validation extraction_validation |
in_progress | The document is waiting for user interaction. Data can be fetched but may change after validation. |
| failed |
(any step) |
(any) | Processing failed. Check the uploaded file for correctness or contact Parashift Support. |
Example API Calls
- Filter for done documents
https://api.parashift.io/v2/documents?filter[status]=done
- Filter for done documents that were not yet exported
https://api.parashift.io/v2/documents?filter[exported_at_blank]=true&filter[status]=done
- Fetch field data for a specific document
https://api.parashift.io/v2/documents/123456/?include=document_fields&extra_fields[document_fields]=extraction_candidates
- Mark a document as exported
https://api.parashift.io/v2/documents/123456/mark_as_exported
- Count documents awaiting Extraction Validation
https://api.parashift.io/v2/documents?filter[workflow_step]=extraction_validation&filter[workflow_status]=in_progress&stats[total]=count