This functionality enables intelligent splitting of a batch document using Machine Learning (ML) to separate it into individual documents.
Machine Learning in action
A Machine Learning (ML) model for document separation is trained on a representative subsample of documents from the entire Parashift Document Center (PDC).
Upon request, tenants can train an individual separation model where:
-
- The generic model serves as a starting point using transfer learning.
- Ground truth data is collected from the corresponding tenant and hierarchy.
- Individual separation models are trained on a predefined schedule, continuously improving as new documents are validated for separation.
Separation Modes
Agentic
Trust Me Bro (TMB).
Thresholds are managed automatically by the Machine Learning model to maximize automation, while keeping errors within an acceptable range.
Cannot be combined with other separation methods.
Explicit
Intelligent separation is configured using manually set confidence thresholds.

Set Up
- Upload Batch Documents: Click the checkbox to upload batch documents.
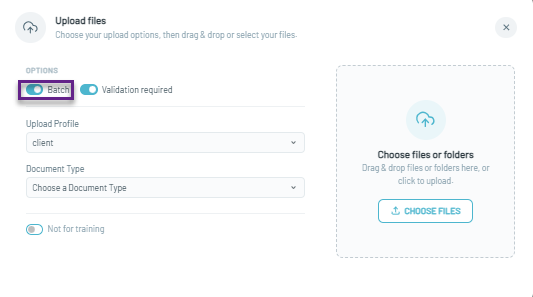
- Perform Separation Validation: You need at least 5 documents to initiate the separation model training in the background. You might need to validate additional documents to improve the model’s accuracy (similar to how classification and extraction models are improved on our platform).
Observe the Model’s Performance:
- Monitor how well the automated separation is working.
- Once you are satisfied with the performance of the intelligent separation model, you can skip the manual separation-validation step by deselecting “MANUAL VALIDATION SEPARATION REQUIRED” in the upload profile.
- Alternatively, you can keep manual validation as part of your process to continuously improve the models.
The list of upload profiles can be found by clicking on "Upload Profiles" in the sidebar.
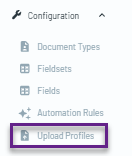
After selecting the correct upload profile, you will find the “Separation Settings” section.

Separation Model
By default, the standard intelligent separation model is used. If you would like to use your own individual separation model, it must be configured by Parashift. The individual model can also be used in your other sub-tenants.
Please request this via support@parashift.io.