A Note from our Head Product
Hello everyone 🖖
sitting down to write the release notes for December I realized that it was quite the slow month 🥱
So I decided to instead write up a little summary of what we have achieved in 2022 🎉 and give some insights into the next big features hitting the Parashift Platform in the beginning of 2023 🔮.
(Don't worry, the improvements and fixes we were able to deploy in December are at the bottom of the page)
🎉 User Interface - balance power users and new user needs
Our app got updates left and right, some bigger, some smaller but overall the usability for our power users has gone up by a ton. We now also want to make it easier for new users to get into the app in 2023, but first, let's look back.
The biggest changes were definitely the 🔥 New Extraction Validation interface, 📜 Visual overhaul of all lists and the focus on promoting the 🏷️ Document Name everywhere.
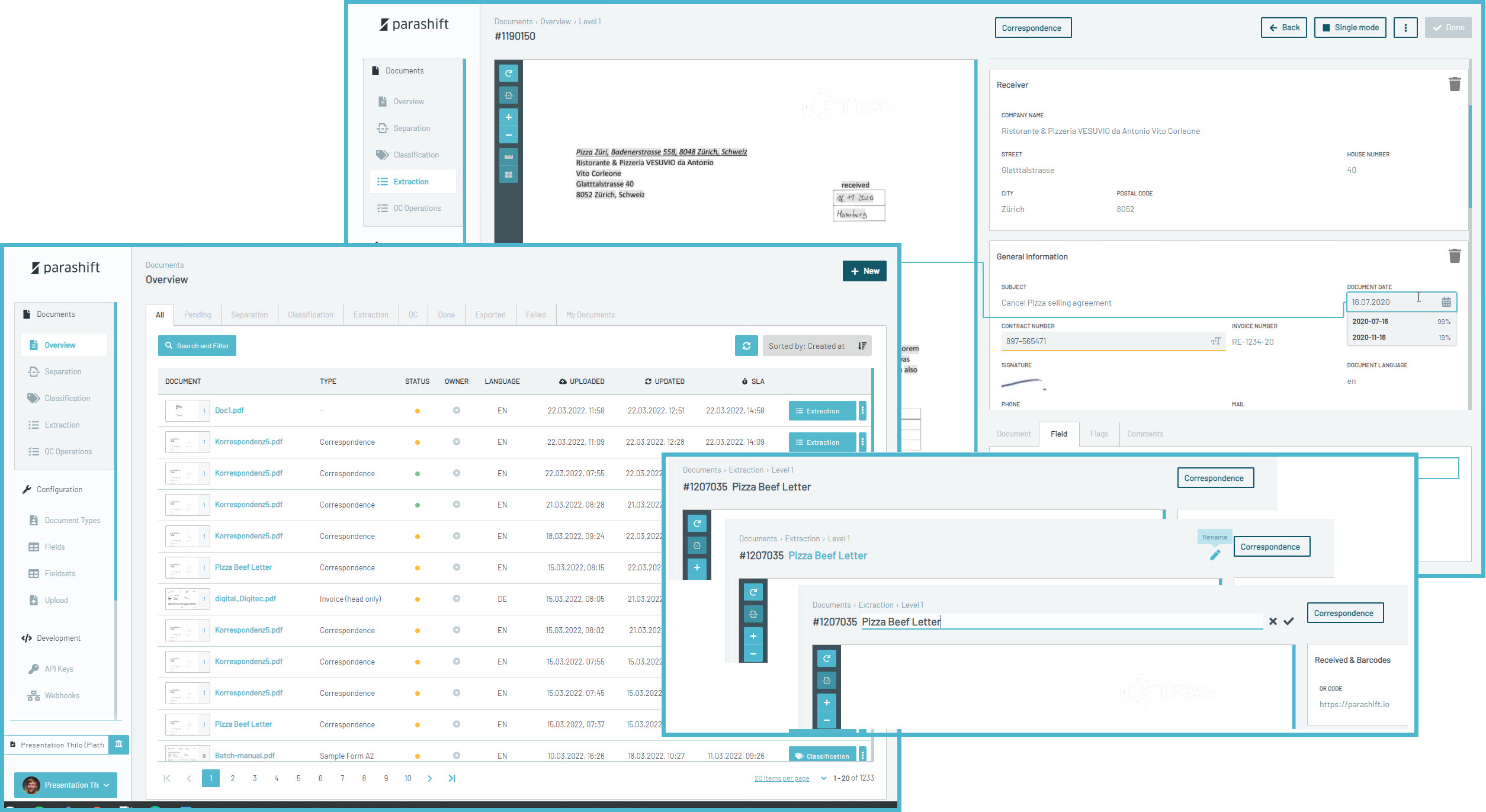
We also greatly improved the 🐎 Performance of all document lists, added 🚚 Bulk Actions to those lists as well as 🥰 Custom Tabs and Filters.
Our focus now for 2023 is two-fold. We want to make the experience working with our Validation interfaces better to speed up Validation work even further. For this, we will tackle the document viewer, re-work it and make it more comfortable to use by adding features such as infinite scrolling (no more "next page buttons"! finally), adding more Field highlighting (especially also for tables) and introducing a fully-fledged line item/table component.
Then there are also lots of small things we can change to just make the overall experience nicer and more polished, stay tuned 😉
💾 Configuration & Processing - harder, better, faster, stronger
Everyone is always excited about nice user interface features, the ones you can see and interact with, but we also added quite a bit underneath the hood that had a big impact on the Platform.
We now support the processing of files other than png, tif, jpg or pdf 🙈. This made the integration for quite some developers easier. It is now also possible to 🔀 Re-order pages and configure more Classification Thresholds 🍾.
Since the Launch of the Platform we added features to also separate batches with lots of pages into single documents and in 2022 we also added a feature to properly export these separated documents into one neat PDF 🐩.
For security and Authentication, we added 🙋 Single Sign On (SSO) as well as 🛑 IP Filtering.
The overall speed 🏎️ to process documents has also gone up significantly, we managed to speed up image creation, Classification and Extraction. Further, we plugged in a new 🍫 Barcode engine speeding this part of the Platform as well as supporting more barcode types.
We will kick off 2023 by working extensively on processing speed, especially in Extraction as well as finally re-vamping the Upload Configuration to give more control and options to users on how to set up their workflows.
And we will add more import options, like automatically processing 📧 E-Mail attachments and later this year also importing documents from OneDrive.
🧠 Machine Learning
Our Platform is not only nicer to look at, or performs better under the hood, but it also got a lot more intelligent. We reworked our core machine learning algorithms leading to new extractors, that revolutionize automated data extraction from documents 💥. We are now able to produce already good predictions for new fields after only one document and will improve on this feature in 2023.
Our goal still is to make the perfect document capture platform, where people can just upload any kind of document and we want to be able to instantly and perfectly tell what kind of document this is and extract the most relevant information from it.
Further, we added a feature to now also use Image features🖼️ for Classification, really helpful for those pesky documents with no text (e.g. plans and medical documents). And of course, we also now support the separation of documents intelligently. 📄
This year we will focus on making our Platform faster, this includes the machine learning part that predicts fields, document types and separation. But we are also working to better utilize pre-existing training data to make our Swarm Learning even more effective.
🔄 One API to rule them all & Integrations
Last year we brought some major new endpoints to our public API. Support for Batches 🗌 and Pages was added as well as support to export the OCR Layout (recognition tokens). We now also fully support applications sending us back ➡️ Feedback to Classification and Extraction results.
Through these changes, we saw the first fully end-to-end integrations into external business applications. From uploading documents to downloading their processed, structured content and then also finally sending back feedback so we can actively learn. This means we can now be truly integrated as a backend document capture service, which is great 😀
Further, we also added a full-blown JobRouter and M-Files integration.
This year we want to focus to bring more application integrations through partners and also bring more features into the API to make integrating us even simpler.
Well, that's it from me for now. I hope everyone had a great 2022 and I am really excited and looking forward to 2023. We have great things planned for Parashift and the Parashift Platform and I am happy to take you all on this ride.
Cheers
Thilo
v22.12 Release Notes
💞 Other Improvements
- Improved Extraction by reducing the amount of predicted false positives
- Better date parsing in Extraction Validation using Point & Shoot
- Upgraded OCR engine and better reading order
- > 160 supported languages
- even better support for handwritten text
- more precise text coordinates
- Validation opens faster through improvements to loading behaviour
🐛 Fixed
- Fields render not properly with big documents
- Document not unlocked after leaving Validation
- Documents item_index on API sometimes wrongly returned as null
- identifier on API sometimes wrong
- false redirect with single sign on (SSO)
- Upload Documents button not properly destroyed on tenant switch
- Fields are endlessly "saving" in Extraction Validation
- Checkboxes missing in Extraction Validation