A Note from our Head Product
Hello everyone 🤗
January was quite a busy month for our development and research & development team. We managed to deploy some big improvements to our Extractors which had a direct impact on Extraction Quality and speed for single fields and addresses.
There is much going on in the background, some cool features to come until the end of the quarter that are (despite the new viewer which is now in Beta) sadly not yet ready to make them public.
We are working on making Highlighting a lot cooler, a new E-Mail attachment import feature, improving Extraction for tables/line items as well as finishing up the new Viewer including a full-blown table editing feature.
So stay tuned for these exciting changes 😁
Cheers
Thilo
👓 New Viewer (Beta)
We have big things planned to speed up Extraction Validation and make it, even more, user-friendly. One bottleneck was however the current Viewer, for which we have gathered a lot of change requests over the last year.
In January we now released the first version (in beta) of the new Viewer. You can activate (and deactivate) it in your personal user settings to get a first look. However, it is not yet meant to be used in production (hence the "beta") as there are still some bugs to squash and perfect the final look & feel of it.
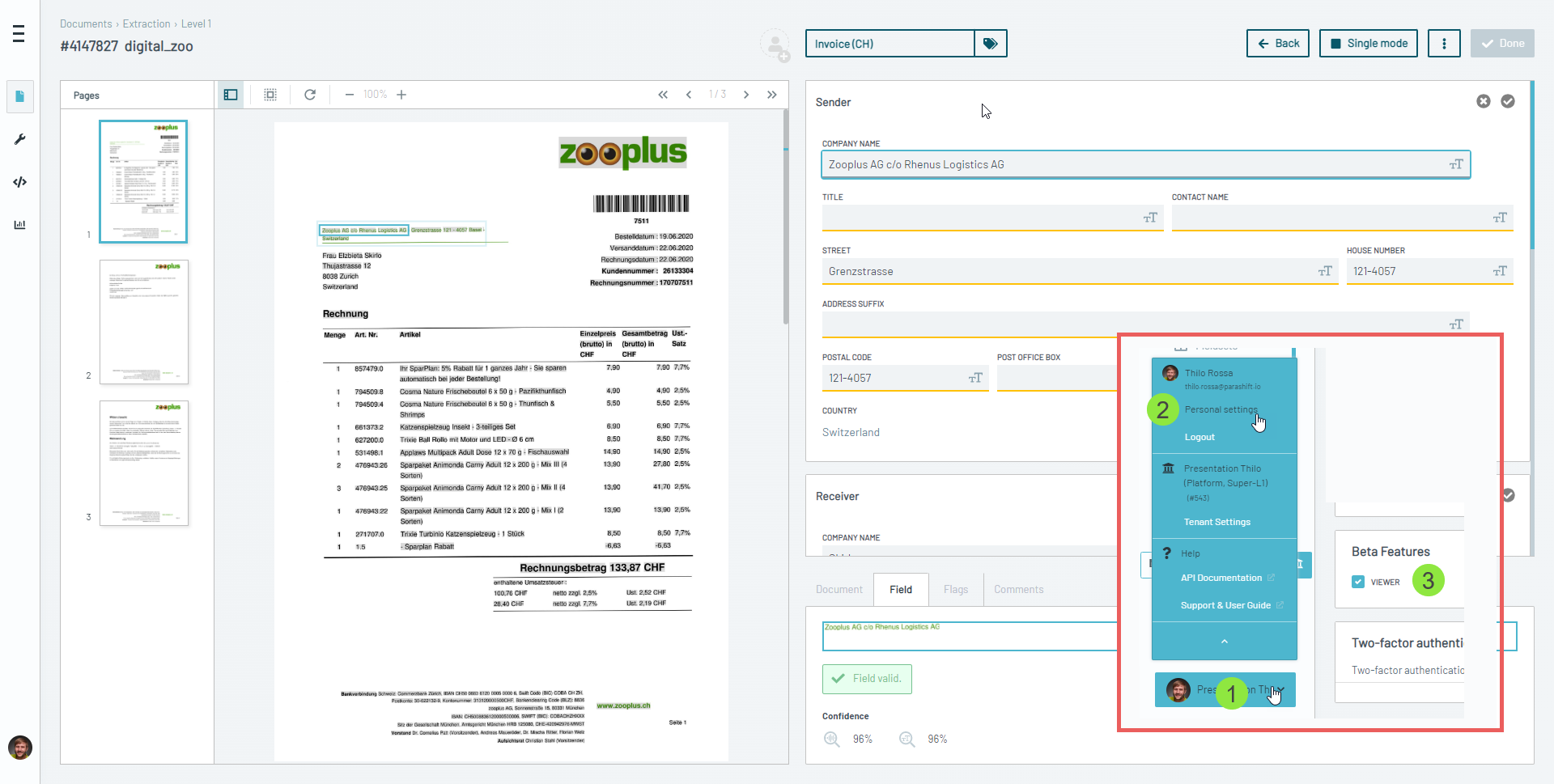
Some of the cool new features in the viewer:
- Endless Scrolling - no more manual page navigation
- Thumbnails - get a preview of the following pages using the thumbnail bar. This bar can be collapsed if you want to give more room to the document
- Easy zooming - Use CTRL + Mousewheel to Zoom in and out
😎 Extraction Quality & Speed improvements
We are on a quest to replace all existing Extractors for all fields and fieldsets with a new technology which helps to get better Extraction Data quality and make processing (a lot) faster.
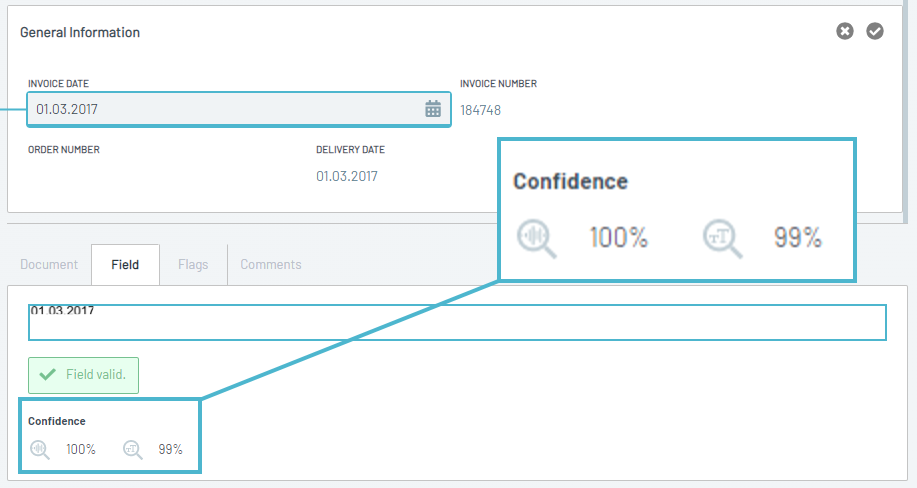
🧱 Single Fields
While still ongoing we already managed to update 85% of existing field configurations, improving extraction quality for certain fields by up to 30%. Average Extraction processing times per page for these fields have also been drastically reduced from 18 seconds to 1.2 seconds!
This technology change also brought the added benefit that new individual fields now already perform a lot better even with very little Training Data.
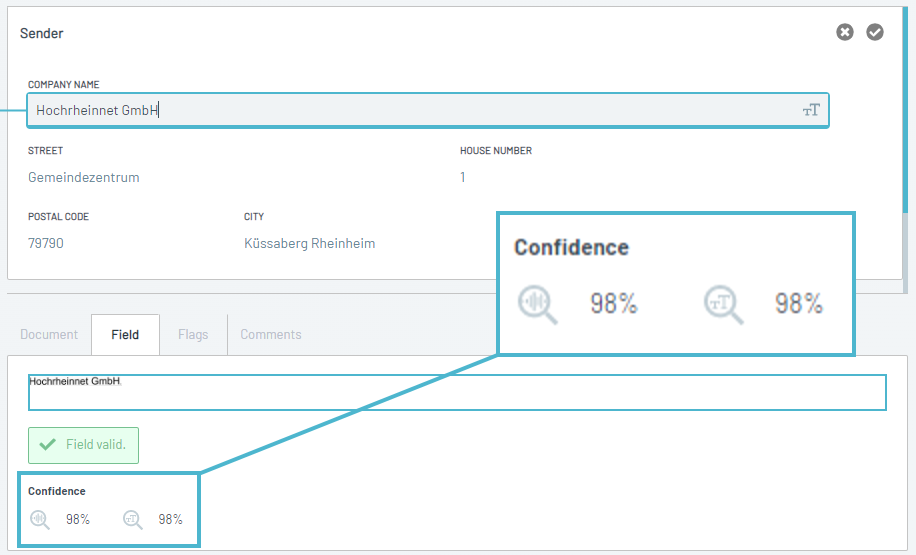
🏙️ Addresses
While also still ongoing we already managed to update 95% of existing address configurations, including two of the most widely used Standard Fields in the Platform, the Sender (Vendor) and Receiver Address.
For these popular Standards, we managed to decrease the Error Rate by 50% while across the board for all addresses Extraction Quality went up.
At the same time, we decreased the Average Extraction processing time per page for addresses from 5.5 seconds to 1.2 seconds.
🍽️ Next Up
(nearly) All that is missing now are "repeatable fieldsets", commonly knows as "line items" or "tables" 😉
We are hard at work to bring the same improvements that we already released for single fields and addresses now also to another one of our most popular fields, the line items, used across different popular document types like invoices, orders or order confirmations.
📃 Faster Loading Times
The first thing you see if you enter our Platform is the good old "Overview" list of all recently uploaded documents. Overall document lists are extensively used by a lot of users, be it for Validation work or just checking on the current runtime data.
So good news everyone, we made them roughly 30% faster by optimizing some database queries 😏
🐛 Fixed
- Folder Upload sets wrong document name
- Parashift Platform App certification renewal
- Boolean fields clickable in document detail view