A Note from our Head Product
Bonjour tout le monde 🙋♂️
Sorry for the long radio silence but we were hard at work to release some big features that had an enormous effect in the background (like Training on deleted documents) but not so much to show for in terms of fancy new features.
However the time of waiting is over and in Q4/2023 we will drop some major cool features once again, mainly focusing on improving Extraction quality.
Our partners already know what's coming due to a sneak peek into our roadmap at our yearly partner event, the rest of you out there need to wait just a little longer but I promise we have some big things coming until the end of the year.
With this said, have fun with the release notes.
Cheers
Thilo 🥚
🪪Train on deleted documents
In today's data-driven world, the ability to delete your data while retaining it as training data in AI projects is a crucial aspect of compliance and information security. It ensures that organizations can uphold privacy regulations and maintain the trust of their customers and stakeholders.
We are thrilled to announce that we have achieved a significant milestone in our data management practices – exactly this ability– to train on deleted Client Identifying Data (CID). 🥳
This breakthrough not only underlines our commitment to privacy and compliance but also exemplifies our dedication to pushing the boundaries of AI innovation.
By harnessing the power of deleted CID for training, we are not only safeguarding sensitive information but also unleashing new opportunities for improving our Document Swarm Learning AI. This exciting development opens doors to a future where data security and technological advancement can coexist harmoniously, enabling us to deliver even smarter and more secure solutions.
🎈 The first compliance-savvy clients have already made the switch, and we will now gradually roll out this new feature globally.
To achieve this big task we had to re-work/extend some of our core capabilities in Extraction & Classification, such as...
🚀 New Classification & Extraction core capabilities
New Classification engine
We have a new Classification Engine that solely relies on cid-deleted save information as its basis for Training and getting better. While our Classification has always been one of the best-performing features in the Platform with the re-write we managed to make it even better 😁
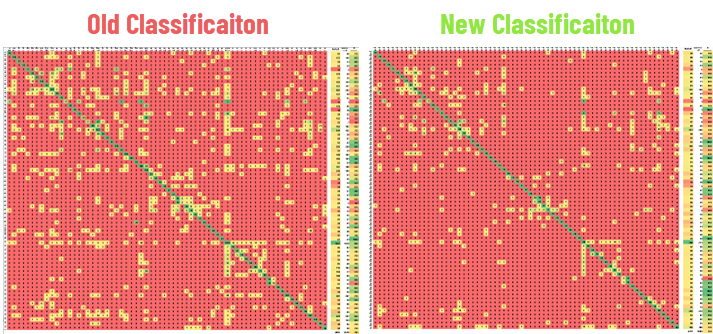
The new Classification engine performs on average roughly 5% better and with no use case we tested it so far worse.
The switch from old to new Classification is now happening seamlessly for all tenants in the next weeks. Before we deploy the new Classification we benchmark every client to make sure that it performs better or at least on par. 👍
So if you feel that Classification suddenly performs better from one day to the next that most likely means you got the new Classification deployed 😎
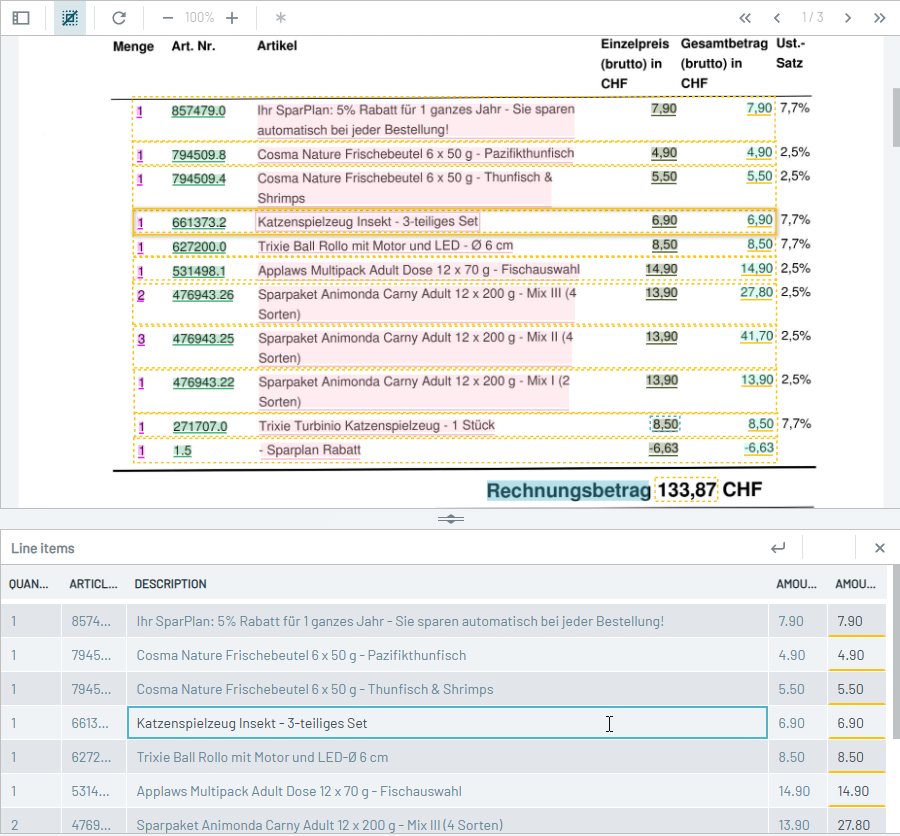
Line item & table Extraction
One of the last remaining "old school" Extraction entities that still relied on non-cid safe Training, line items, and tables, was also switched to utilize our newest capabilities. This not only sped up Extraction once again by a couple of seconds it also overall led to more accurate and stable table and line item Extraction. 🛳️
🎆New Highlighting & Connection Line
The new default highlighting is finished and with it came an updated version of the connection line to better showcase where we extracted the value from. In the screenshot above you can see the table highlighting in action, showing boxes around rows and different colors for columns.
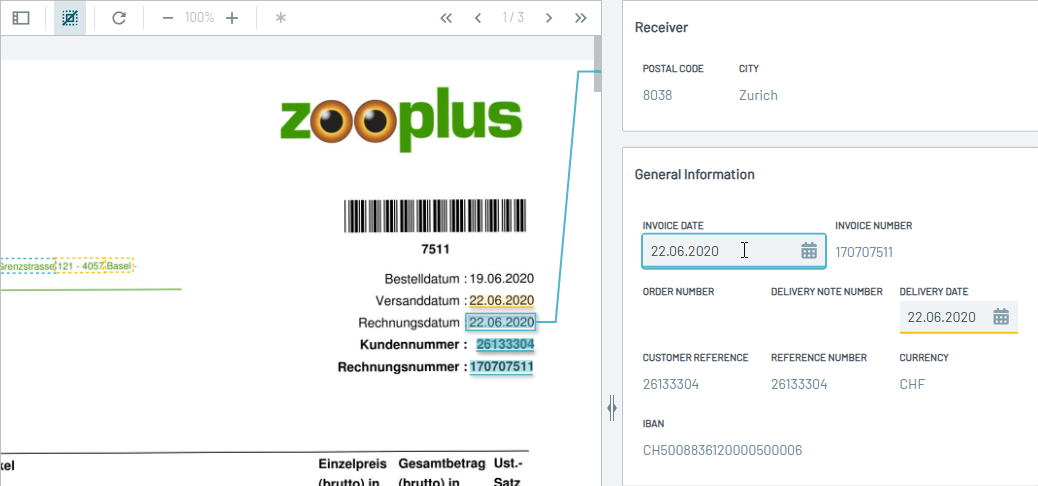
For each section you can now easily configure if you want it displayed as a table or repeatable fields and if you want separate row (box) or column (color) highlighting. We applied the new highlighting to all our standards, so if you are using them you should already come into the pleasure of Extraction Validation looking a lot prettier.
🤫 For all the power users out there we are also releasing a new "aggressive" highlighting. It won't look as pretty but will convey a lot more information in one glance. (The best part is it will use a color named "Laser Lemon" 🍋 )
💸Regional extension Standard Invoices
At first glance, the data you want extracted from an Invoice is pretty similar worldwide, the vendor, invoice number, data, total amounts, and maybe line items if you want to match it to an order. But on second glance there can be quite the differences depending on the industry or location. One industry may heavily rely on the delivery address, another industry deeply cares about the weight of articles, one country needs to have the total amounts split by value-added tax rate the next region needs them split by state and federal tax...
Through our Parashift Swarm Learning, we were always able to cater to these special needs by allowing users to simply add more standard fields or create new fields if none of our standards fit their need. To make this process faster (swapping fields in/out) we split up our "Invoice" document type into multiple standards that give a better starting point for configuration.
- US Invoice - total amounts split by federal & state tax (and more)
- DE Invoice - total amounts split by tax rate
- CH Invoice - total amounts split by tax rate, with QR invoice code
- Logistics Invoice - added delivery address and line items with weight
- ...
Again, you can always change our Standards to your needs but this should make it easier and faster 😉
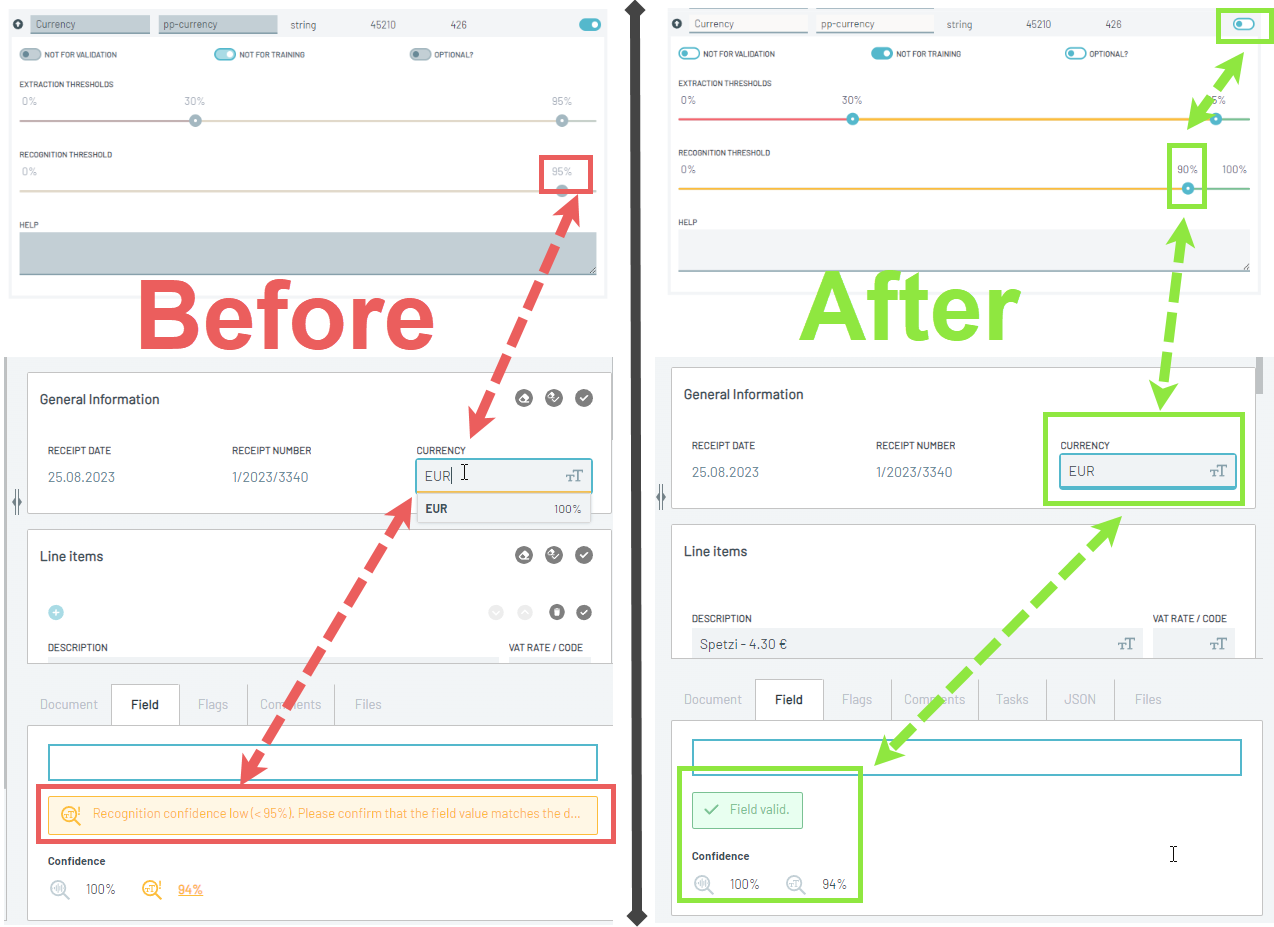
💬 Configurable Recognition (OCR) Threshold
Every time we extract data we produce two confidence scores (0-100%).
- prediction confidence: How sure is the machine that it predicted the correct value?
- recognition confidence: How sure is the machine that it read this predicted value correctly?
You were always able to set a threshold on the prediction confidence to automatically set a warning if the system was e.g. under 90% sure that it found the correct value and ask for user validation. But the recognition confidence, which is especially important with e.g. documents that are handwritten or are badly scanned, was hard-coded at 95%.
We made this now also configurable allowing more granular configuration. In the following example you can see that we predicted the correct value for the currency but recognition confidence was only 94%. Before it would produce a warning while now you can just set the threshold a little lower to have it processed fully automatically.
🤏All the small things
🪝 Webhooks
We re-wrote our webhook backend to make webhooks more reliable and also updated the documentation with the exact strategy we use for "Retries & Exponential Backoff".
👤 Authentication & Authorization
A lot of work went into this topic in the background to make it more secure and faster. The changes will be rolled out in the next weeks step-by-step and enable us to work on bigger topics like a Partner Admin module and more.
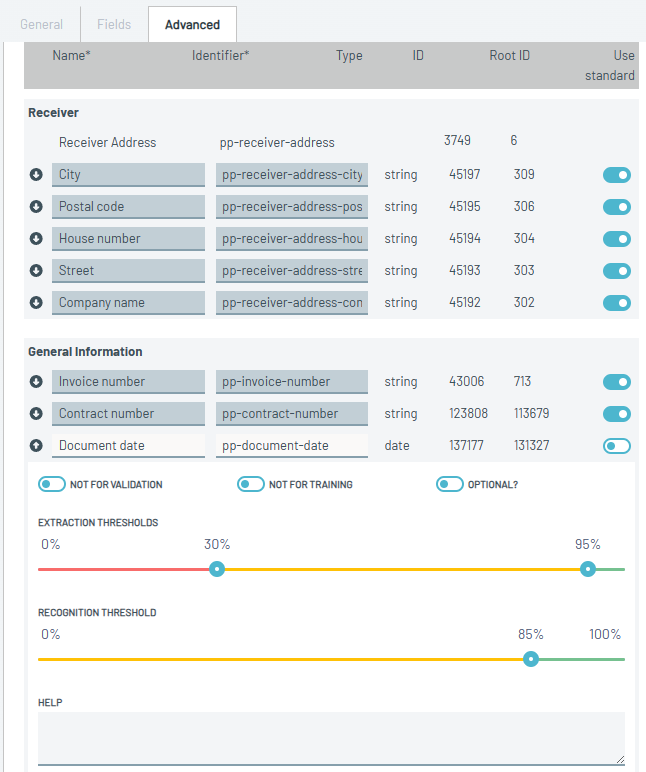
🫧Cleaned up "Advanced" tab in document type configuration
The "Advanced" tab got a slight overhaul to make it cleaner and better understandable on one look.
🍟 Faster "clear", "confirm" and "clear & confirm"
Clearing or confirming a section as well as clearing & confirming a section were drastically sped up to minimize Validation time.
🦸 Prevent common configuration mistake with multiple single fields as repeatable
We enhanced the document type configuration logic to prevent a common configuration mistake by not allowing users to mark a section as repeatable anymore if it has anything other then a single field or a fieldset inside.
🥸 Empty fieldsets now also adhere to general validation logic
If you clear a section the remaining empty row of fields now also properly adheres to validation logic. Before we auto-validated the fields which led to some confusion.
🐛 Fixed
- Time Logs in serial mode are now logged correctly
- soft resets no longer clear validated_at timestamp
- fixed weird behavior with Viewer and rotating pages
- opening the table module no longer hides parts of the document
- the previews in document lists of documents created from a batch through separation now properly show the first page of the document (not batch)